
多模態應用是當前AI領域最熱門的發展方向之一,它允許AI系統同時處理文字、影像、語音等多種形式的資料。在這篇技術文章中,我將帶領大家探索如何利用大模型語言(LLM)開發功能強大的多模態應用,並透過實際案例展示完整的開發流程。
客製化提示詞改變AI行為模式
在開發多模態應用時,提示詞的設計至關重要。透過修改提示詞字首,我們可以徹底改變AI的行為模式。以下是一個將AI轉變為兒童故事講述者的例子:
PREFIX = """
You are a story teller for children.
You read aloud stories based on pictures that the user pass you.
You always start your story with a welcome message targeting children, with the
goal of make them laugh.
You can use multiple tools to answer the question.
ALWAYS use the tools.
You have access to the following tools:
"""
agent = initialize_agent(toolkit.get_tools(), model,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose = True,
agent_kwargs={
'prefix':PREFIX})
這段程式碼透過設定PREFIX變數來自訂AI的行為模式。它定義了一個專門為兒童講故事的AI角色,指定了AI需要根據使用者提供的圖片講故事,並總是以能讓孩子們發笑的歡迎語開始。最後透過initialize_agent函式將這個自訂提示詞應用到代理上。這種方法讓我們可以在不修改底層模型的情況下,靈活地調整AI的行為風格和輸出方式。
值得注意的是,每個預構建的代理都有自己的提示詞範本,因此在客製化之前,建議先檢查原有範本,以確保修改不會破壞代理的核心功能。
發票分析應用:CoPenny的實作
現在讓我們開始構建一個實際的多模態應用 - 一個名為CoPenny的發票分析助手。這個應用能夠自動分析發票並朗讀重要訊息,為企業和個人節省大量手動處理時間。
檔案處理自動化的價值
檔案處理自動化是一種使用技術來簡化和自動化組織內各種檔案相關任務和流程的策略。它涉及使用包括檔案捕捉、資料提取、工作流程自動化和與其他系統整合的軟體工具。例如,檔案處理自動化可以幫助你從發票、收據、表格和其他型別的檔案中提取、驗證和分析資料。
數位流程自動化(DPA)是一個更廣泛的術語,指的是使用數位技術自動化任何業務流程。DPA可以幫助你連線應用程式、資料和服務,透過雲流程提高團隊生產力。DPA還可以幫助你建立更複雜和直觀的客戶體驗,促進組織協作,並利用AI和機器學習進行創新。
CoPenny開發步驟
- 首先,我們使用Azure認知服務工具包,特別選擇表單辨識器和文字轉語音工具:
toolkit = AzureCognitiveServicesToolkit().get_tools()
# 這些工具在列表的第一和第三個位置
tools = [toolkit[0], toolkit[2]]
tools
工具包含了兩個關鍵元件:
- AzureCogsFormRecognizerTool:用於從檔案中提取文字、表格和鍵值對
- AzureCogsText2SpeechTool:用於將文字轉換為語音
- 接下來,我們使用一張範例發票來測試代理的功能:
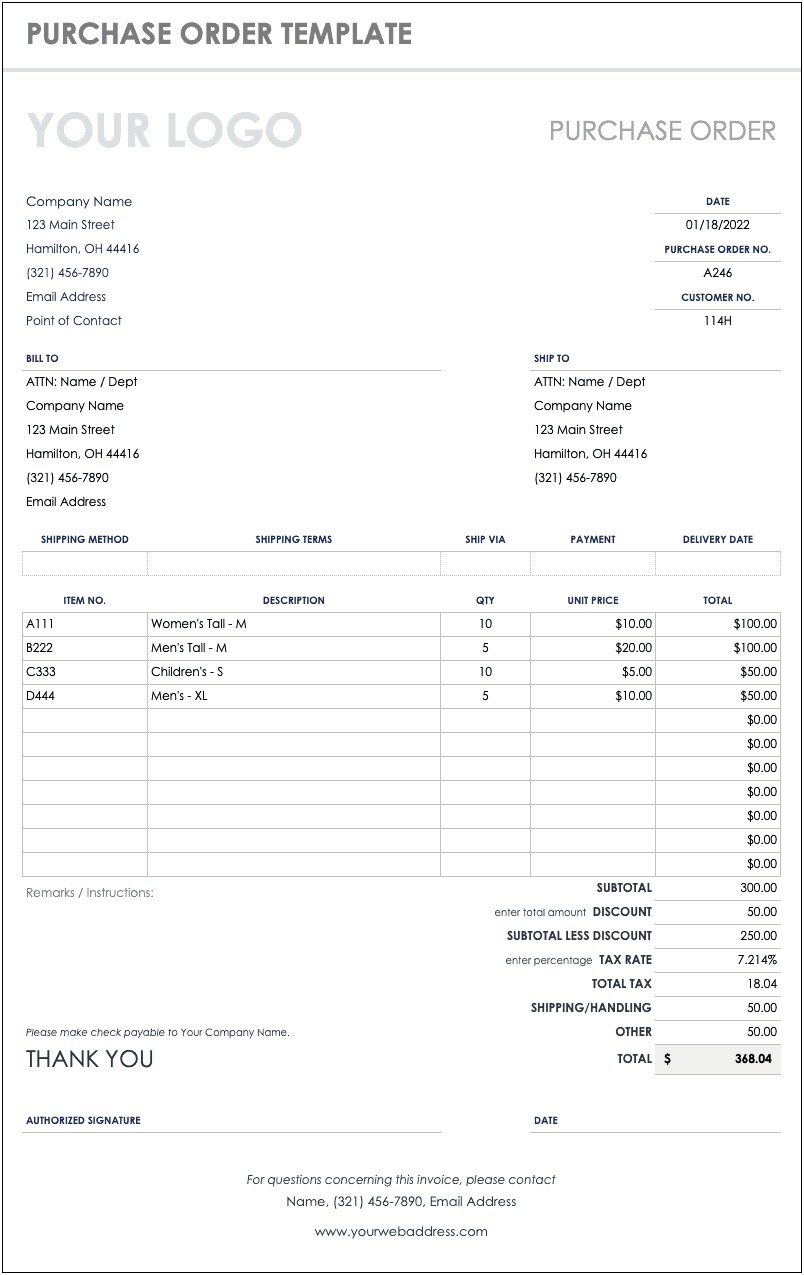
- 讓我們詢問模型發票中所有男性商品的SKU:
agent.run("what are all men's skus? "
"https://www.whiteelysee.fr/design/wp-content/uploads/2022/01/customt-shirt-order-form-template-free.jpg")
模型回答:“The men’s skus are B222 and D444.”
- 我們還可以一次詢問多項訊息,如女性商品SKU、配送地址和交付日期:
agent.run("give me the following information about the invoice: women's SKUs, shipping address and delivery date."
"https://www.whiteelysee.fr/design/wp-content/uploads/2022/01/customt-shirt-order-form-template-free.jpg")
模型回答:“The women’s SKUs are A111 Women’s Tall - M. The shipping address is Company Name 123 Main Street Hamilton, OH 44416 (321) 456-7890. The delivery date is not mentioned in the invoice.”
- 我們還可以利用text2speech工具將回應轉換為語音:
agent.run("extract women's SKUs in the following invoice, then read it aloud:"
"https://www.whiteelysee.fr/design/wp-content/uploads/2022/01/customt-shirt-order-form-template-free.jpg")
- 為了讓代理更好地滿足我們的需求,我們可以定製提示詞,使其在每次回應時自動生成語音輸出:
PREFIX = """You are an AI assistant that help users to interact with invoices. You extract information from invoices and read it aloud to users. You can use multiple tools to answer the question.
Always divide your response in 2 steps:
1. Extracting the information from the invoice upon user's request
2. Converting the transcript of the previous point into an audio file
ALWAYS use the tools.
ALWAYS return an audio file using the proper tool.
You have access to the following tools:
"""
agent = initialize_agent(tools, model,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose = True,
agent_kwargs={
'prefix':PREFIX})
- 執行代理:
agent.run("what are women's SKUs in the following invoice? :"
"https://www.whiteelysee.fr/design/wp-content/uploads/2022/01/customt-shirt-order-form-template-free.jpg")
現在,即使用者沒有明確要求,代理也會自動將回答儲存為音訊檔案。
在這個實作中,我們看到了如何將多個AI工具結合起來建立一個實用的發票分析應用。首先使用表單識別器從發票影像中提取文字訊息,然後根據使用者查詢回傳特定訊息,最後使用文字轉語音工具將回答轉換為音訊。透過自定義提示詞,我們成功地讓代理在每次回應時自動執行這兩個步驟,而無需使用者明確指示。
這個案例展示了多模態AI應用的強大潛力 - 它不僅能處理視覺資料(發票影像),還能生成音訊輸出,大提高了使用者與資料互動的便利性。
構建YouTube評論生成器:GPTuber
接下來,讓我們探索另一種多模態應用的實作方式 - 將單個工具組合成一個代理。我們的目標是構建一個名為GPTuber的助手,它能夠幫助我們生成YouTube影片的評論,並在社交媒體上發布這些評論,同時配上漂亮的描述和相關圖片。
這個代理需要執行以下步驟:
- 根據我們的輸入搜尋並轉錄YouTube影片
- 根據轉錄內容,按照使用者指定的長度和風格生成評論
- 生成與影片和評論相關的圖片
YouTube工具與Whisper語音辨識
第一步是搜尋並轉錄YouTube影片。為此,我們需要兩個工具:
- YouTubeSearchTool:LangChain提供的開箱即用工具,改編自github.com/venuv/langchain_yt_tools。使用範例:
from langchain.tools import YouTubeSearchTool
tool = YouTubeSearchTool()
result = tool.run("Avatar: The Way of Water,1")
result
輸出:
"/watch?v=d9MyW72ELq0&pp=ygUYQXZhdGFyOiBUaGUgV2F5IG9mIFdhdGVy"
這個工具回傳影片的URL。要觀看它,可以將其增加到https://youtube.com網域名稱後。
- CustomYTTranscribeTool:這是一個自定義工具,改編自github.com/venuv/langchain_yt_tools。它使用語音轉文字模型來轉錄從上一個工具檢索到的音訊檔案。
在這一部分,我們開始構建GPTuber應用的基礎。YouTubeSearchTool允許我們根據關鍵字搜尋YouTube影片,而CustomYTTranscribeTool則能夠將影片的音訊內容轉錄為文字。這兩個工具結合使用,為我們的代理提供了處理YouTube影片內容的能力。
這種方法的優勢在於我們可以靈活地組合不同的工具,根據特定需求開發定製化的多模態應用。相比於使用預構建的工具包,這種方法提供了更大的自由度和擴充套件性。
在下一部分,我們將繼續探索如何完成GPTuber的剩餘功能,包括評論生成和相關圖片建立。
深入理解Whisper:OpenAI的開放原始碼語音轉錄利器
Whisper是OpenAI於2022年9月發布的轉換器(Transformer)架構模型,專為語音識別與轉錄設計。與大多數OpenAI模型不同,Whisper是完全開放原始碼的,這讓開發者可以自由地將其整合到各種應用中。
Whisper的工作原理與架構
Whisper的處理流程包含幾個關鍵步驟:
- 音訊切分與頻譜轉換:將輸入音訊分割成30秒的片段,並轉換為聲音訊率的視覺表示(頻譜圖)
- 編碼器處理:這些頻譜圖被傳送給編碼器(Encoder)進行處理
- 隱藏狀態生成:編碼器產生一系列隱藏狀態(Hidden States),捕捉音訊中的關鍵訊息
- 解碼器預測:解碼器(Decoder)預測對應的文字內容,使用特殊標記指示任務型別(語言識別、語音轉錄或語音翻譯)和輸出語言
- 時間戳生成:解碼器還可以為轉錄內容中的每個詞或短語生成時間戳
Whisper的強大之處在於它能夠處理多種語言、識別不同口音,並在嘈雜的環境中依然保持較高的準確性。
實際應用Whisper進行語音轉錄
由於Whisper模型只接受檔案輸入而非URL,在自定義工具中,我們需要先從影片URL下載內容為.mp4檔案。以下是使用Whisper進行影片轉錄的核心程式碼:
import openai
# 開啟下載好的影片檔案
audio_file = open("Avatar The Way of Water Official Trailer.mp4", 'rb')
# 使用Whisper模型進行轉錄
result = openai.Audio.transcribe("whisper-1", audio_file)
# 關閉檔案並輸出轉錄結果
audio_file.close()
print(result.text)
這段程式碼展示了Whisper模型的基本使用流程。首先,我們匯入OpenAI函式庫,然後以二進位模式開啟影片檔案。接著,呼叫openai.Audio.transcribe()方法,傳入Whisper模型名稱(“whisper-1”)和音訊檔案物件。模型處理完成後,我們關閉檔案並列印轉錄結果。這個簡單的流程就能將複雜的音訊內容轉換為文字,無需複雜的預處理或後處理步驟。
執行上述程式碼後,我們得到了《阿凡達:水之道》預告片的完整轉錄內容:
♪ Dad, I know you think I'm crazy. But I feel her. I hear her heartbeat. She's so close. ♪ So what does her heartbeat sound like? ♪ Mighty. ♪ We cannot let you bring your war here. Outcast, that's all I see. I see you. ♪ The way of water connects all things. Before your birth. And after your death. This is our home! I need you with me. And I need you to be strong. ♪ Strongheart. ♪
構建多模態工具鏈
在多模態應用中,我們通常需要將不同的工具串聯起來,形成一個完整的處理流程。在這個例子中,我們將YouTube搜尋工具與Whisper轉錄工具結合,實作從影片搜尋到內容轉錄的一站式服務。
初始化工具與代理
以下是如何初始化工具列表和代理(Agent)的程式碼:
from langchain.agents import initialize_agent, AgentType
from langchain.llms import OpenAI
# 初始化LLM模型
llm = OpenAI(temperature=0)
# 建立工具列表
tools = []
tools.append(YouTubeSearchTool())
tools.append(CustomYTTranscribeTool())
# 初始化代理
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 執行代理任務
agent.run("search a video trailer of Avatar: the way of water. Return only 1 video. transcribe the youtube video and return the transcription.")
這段程式碼展示瞭如何使用LangChain框架建立一個能夠協調多個工具的人工智慧代理。首先,我們初始化一個OpenAI語言模型作為代理的大腦,設定temperature=0確保輸出的一致性和確定性。接著,我們建立一個工具列表,包含YouTube搜尋工具和自定義的YouTube轉錄工具。然後使用initialize_agent()函式初始化代理,選擇ZERO_SHOT_REACT_DESCRIPTION作為代理型別,這意味著代理將根據工具描述做出決策,而不需要任何範例。最後,我們透過agent.run()方法執行任務,請求代理搜尋《阿凡達:水之道》的預告片並回傳轉錄內容。
執行該程式碼後,代理會按照以下步驟工作:
- 分析任務,確定需要先搜尋影片,然後轉錄
- 呼叫
youtube_search工具搜尋影片 - 取得影片URL
- 呼叫
CustomeYTTranscribe工具轉錄影片 - 回傳轉錄結果
這個過程展示了LLM代理如何根據任務需求有條理地協調不同工具。
DALL-E:從文字到影像的創造性轉換
除了處理音訊和文字,我們還可以在多模態應用中生成影像。DALL-E是OpenAI於2021年1月推出的影像生成模型,能夠根據文字描述建立影像。
DALL-E的技術基礎
DALL-E根據GPT-3架構,但經過了專門的訓練,使其能夠理解文字描述並生成對應的視覺內容。它透過以下方式工作:
- 模型在大量文字-影像對上進行訓練
- 使用標記(token)詞彙表同時表示文字和影像概念
- 能夠為相同的文字生成多個影像,展示不同的解釋和變化
在LangChain中使用DALL-E
LangChain提供了與DALL-E的原生整合,可以輕鬆地將其作為工具使用:
from langchain.agents import load_tools
from langchain.agents import initialize_agent
# 載入DALL-E工具
tools = load_tools(['dalle-image-generator'])
# 初始化代理
agent = initialize_agent(
tools,
model,
AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 建立萬聖節夜晚的影像
agent.run("Create an image of a halloween night. Return only the image url.")
這段程式碼展示瞭如何在LangChain框架中整合DALL-E影像生成功能。load_tools()函式使得載入預定義工具變得簡單,我們只需指定’dalle-image-generator’作為引數。初始化代理後,我們請求建立一個萬聖節夜晚的影像。代理會理解這個請求,呼叫DALL-E工具,並最終回傳生成的影像URL。這種整合方式的優雅之處在於,我們無需直接處理API呼叫的細節,整個過程由LangChain框架和代理系統優雅地處理。
當代理執行這個任務時,它會使用DALL-E生成一個符合描述的影像,如"一個陰森的萬聖節夜晚,天空中有滿月和飛行的蝙蝠,背景是一座鬼屋"。
生成影片評論
除了影像生成,我們還可以讓代理根據影片轉錄生成評論:
# 搜尋影片並生成評論
agent.run("search a video trailer of Avatar: the way of water. Return only 1 video. transcribe the youtube video and return a review of the trailer.")
執行這個請求時,代理會嘗試使用現有工具執行任務,但會發現沒有專門的"寫評論"工具。有趣的是,代理能夠意識到這一點,並轉而使用自己的引數知識(即LLM的內建能力)來生成評論:
Final Answer: Avatar: The Way of Water trailer is visually stunning and captivating. The trailer gives a glimpse into the world of Pandora and the connection between the Na'vi and the way of water. The music and sound effects add to the overall immersive experience. The trailer leaves the audience wanting more and eagerly anticipating the release of the movie.
這展示了LLM作為推理引擎的強大能力,以及它們具備的常識推理能力。當遇到沒有專門工具的任務時,它能夠回退到使用自身知識。
整合所有工具:構建完整的多模態代理
現在我們已經分別測試了各個工具,接下來要將它們整合到一個統一的代理中,實作從影片搜尋、轉錄到評論和影像生成的完整流程。
構建工具集合
首先,我們需要將DALL-E工具增加到之前的工具列表中:
# 建立完整工具列表
tools = []
tools.append(YouTubeSearchTool())
tools.append(CustomYTTranscribeTool())
tools.append(load_tools(['dalle-image-generator'])[0])
# 檢查工具名稱
[tool.name for tool in tools]
執行以上程式碼,我們得到的工具列表為:['youtube_search', 'CustomeYTTranscribe', 'Dall-E Image Generator']
初始化完整代理
接下來,我們使用這個完整的工具列表初始化代理:
# 初始化代理
agent = initialize_agent(
tools,
model,
AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
這段程式碼將我們前面討論的所有工具整合到一個統一的代理系統中。我們建立了一個包含YouTube搜尋、影片轉錄和DALL-E影像生成功能的工具列表。load_tools(['dalle-image-generator'])[0]語法中的[0]是因為load_tools回傳的是一個工具列表,即使我們只請求了一個工具。透過列印工具名稱,我們確認所有工具都已正確載入。最後,我們使用這個完整的工具集初始化代理,為後續的複雜任務做好準備。
透過這種方式,我們建立了一個能夠處理多種模態(文字、音訊、影像)的強大代理。這個代理能夠執行複雜的任務鏈,如搜尋影片、轉錄內容、生成評論,甚至建立相關的影像。
提升代理效能的提示工程
在實際應用中,我們可能需要透過提示工程(Prompt Engineering)來最佳化代理的行為。例如,我們可以:
- 為代理提供更詳細的任務描述
- 指定輸出格式要求
- 設定決策優先順序
- 提供評估標準
透過精心設計的提示,可以顯著提高代理在複雜任務中的表現,減少錯誤和混淆,提供更符合使用者期望的結果。
多模態應用的實際價值與挑戰
構建多模態應用不僅是技術上的挑戰,也是為使用者創造更豐富、更自然互動體驗的機會。透過整合語音、文字和影像處理能力,我們可以建立更接近人類感知方式的系統。
多模態應用的潛在用途
這種整合了多種感知模式的應用有著廣泛的應用前景:
- 內容創作助手:幫助創作者從影片中提取靈感,生成評論和相關影像
- 教育工具:將影片講座轉錄為文字,生成視覺摘要和學習資料
- 媒體分析系統:分析影片內容,生成摘要、評論和視覺表示
- 無障礙技術:為聽障人士提供影片轉錄,為視障人士提供內容描述
技術挑戰與
開發人工智慧化多模態應用:代理工具的無縫整合
在人工智慧應用開發領域,多模態功能已成為提升使用者經驗的關鍵。透過結合文字、影像、音訊等不同形式的資料,我們可以建立更加豐富與實用的應用程式。在這篇文章中,我將分享如何運用大模型語言(LLM)結合各種工具,開發能夠自動執行複雜任務的多模態應用。
多模態代理的實際運作機制
多模態代理能夠協調多種工具完成複雜任務,例如從YouTube影片生成評論並建立相關圖片。這種應用的核心在於如何讓LLM人工智慧地選擇和使用適當的工具,同時保持任務流程的連貫性。
以下是一個實際的代理執行過程,這個代理被指示從YouTube上尋找《阿凡達:水之道》的預告片,為其生成評論並建立相關圖片:
agent.run("幫我找出'阿凡達:水之道'的預告片,為其轉錄內容並生成評論。根據轉錄內容生成一張圖片")
這段程式碼啟動了一個代理執行器,指示它完成一系列任務:搜尋特定影片、轉錄內容、生成評論和建立圖片。這個簡單的指令會觸發複雜的工作流程,代理會自動決定使用哪些工具以及執行順序。
當執行這段程式碼時,代理會經歷以下步驟:
- 搜尋YouTube找到《阿凡達:水之道》的預告片
- 使用轉錄工具取得預告片的對話和內容
- 根據轉錄內容撰寫評論
- 使用DALL-E等影像生成工具建立相關圖片
代理執行的輸出結果會包含完整的思考過程:
> Entering new AgentExecutor chain...
I need to search for a video trailer of "Avatar: The Way of Water" and transcribe it
to generate a review. Then, I can use the transcription to generate an image based
on the video content.
Action: youtube_search
Action Input: "Avatar: The Way of Water trailer,1"
Observation: ['/watch?v=d9MyW72ELq0&pp=ygUgQXZhdGFyOiBUaGUgV2F5IG9mIFdhdGVyIHRyYWlsZXI%3D']
Thought: I found a video trailer of "Avatar: The Way of Water" with the given search query.
Now I need to transcribe the video and generate a review.
Action: CustomeYTTranscribe
Action Input: '/watch?v=d9MyW72ELq0&pp=ygUgQXZhdGFyOiBUaGUgV2F5IG9mIFdhdGVyIHRyYWlsZXI%3D'
Observation: ♪ Dad, I know you think I'm crazy. [...]
這段輸出展示了代理的思考過程和行動軌跡。每一步都清晰可見:從決定需要搜尋影片,到執行YouTube搜尋,再到使用自定義轉錄工具。代理會思考每個步驟的結果並決定下一步行動,這種透明的思考過程是代理系統的核心價值。
最終,代理會使用DALL-E影像生成器建立根據評論內容的圖片,並提供完整的評論:
Action: Dall-E Image Generator
Action Input: "Review of Avatar: The Way of Water trailer: The trailer for Avatar:
The Way of Water is captivating and mysterious. It starts with a dialogue between
a father and his son, discussing a connection to someone or something. The visuals
are stunning, showcasing breathtaking landscapes and vibrant underwater scenes..."
Observation: [image_url]
Final Answer: The "Avatar: The Way of Water" trailer is captivating and mysterious,
featuring stunning visuals of landscapes and underwater scenes. It hints at an
impending war and explores the theme of water and its connection to all things.
The trailer leaves viewers excited and intrigued about the upcoming movie.
提升代理效能:最佳化提示範本
為了讓代理更好地滿足特定需求,我們可以透過最佳化提示範本來引導代理的行為。以下是一個更加專業化的提示範本範例:
PREFIX = """
You are an expert reviewer of movie trailer.
You adapt the style of the review depending on the channel the user want to use,
namely Instagram, LinkedIn, Facebook.
You can use multiple tools to answer the question.
ALWAYS search for the youtube video related to the trailer. Search ONLY 1 video.
ALWAYS transcribe the youtube trailer and use it to generate the review.
ALWAYS generate an image alongside the review, based on the transcription of the trailer.
ALWAYS use all the available tools for the various steps.
You have access to the following tools:
"""
agent = initialize_agent(tools, model, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
agent_kwargs={'prefix':PREFIX})
這段程式碼建立了一個專門用於電影預告評論的代理,並透過PREFIX變數定義了詳細的指令。這些指令包括:
- 明確代理的專業身份(電影預告評論工作者)
- 指定代理應根據不同社交平台調整評論風格
- 提供明確的工作流程指令(搜尋、轉錄、生成圖片)
- 使用"ALWAYS"強調必須執行的步驟
這種明確的指令能大幅提升代理的執行品質,讓其行為更可預測與符合特定需求。當代理接收到特定請求時,它會嚴格遵循這些指令:
agent.run("為'阿凡達:水之道'的預告片生成評論。我想將其發布在Instagram上。")
代理會按照指定的工作流程執行任務,並且特別注意調整輸出風格以適合Instagram平台,包括使用相關標籤和簡潔有力的語言。
